学完高等数学可以做哪些有意思的事情?
这个问题实在是太大了,展开讲三天也讲不完,因为数学+编程能做的有意思的事情实在是太多了。你随意找一个方向,左手捧一套高数右手捧一台电脑,一头扎下去,相信都能找到无数可以摆弄的事情。在此结合自己做过的项目给你讲讲高数的应用(省略全部数学细节)。
一、图形学
图形学的目标是创造一个真实的三维场景供你在里面漫游,它是所有三维游戏的基础。它的原理很简单,在一个空间里放上三角形、箱子、机器人或云,摆好摄像头,放置光源,然后计算摄像头应该看到什么,把结果显示在电脑屏幕上。不仅是静态的成像,动态的物理过程也可以实现,比如雾、碰撞、重力等等。

辐射3截图
1.1 三维漫游
你可以用OpenGL和C++轻松实现一个三维漫游程序(流畅性优先),然后不断往里面添加各种模型(球体、三角面片几何体、飞机)和属性(遮挡、抗锯齿、透明、玻璃、爆炸),最终把你的漫游程序变成一个精美的实时游戏。
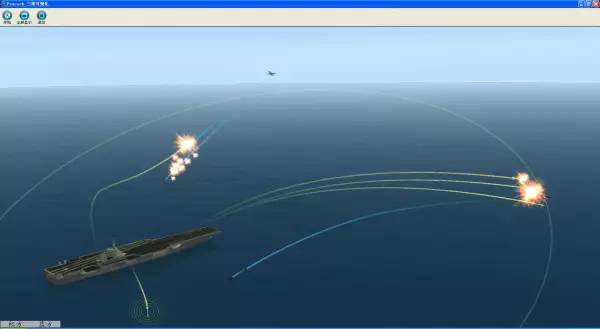
三维海战(图片来自百度图片)
1.2 光线追踪器
可以着重研究光线是如何照射和成像的(精美性优先),实现各种相机(双目、鱼眼、弱投影),材质(金属、玻璃),光源类型(点光源、方向光源、区域光源)以及光照模型(BRDF、路径追踪),最终你想画啥都能画得惟妙惟肖。光线追踪器的渲染速度很慢,程序要追踪海量光线的反射和折射分量,比如下方的钻石图案需要运行5分钟才能画完。虽然不能实时移动和旋转相机,但是渲染的结果极其逼真。

用C++实现的玻璃材质

用光线追踪器pov-ray画的钻石
1.3 基于GPU的加速渲染
当然,你也可以兼顾渲染质量和动画帧速,这个时候就需要使用更强大的计算资源,可以并行计算的GPU是不二的选择。看看CUDA的代码,你可以做一个体渲染模块来实时观察CT图像,卖给医学图像处理公司(也许)能赚大钱。
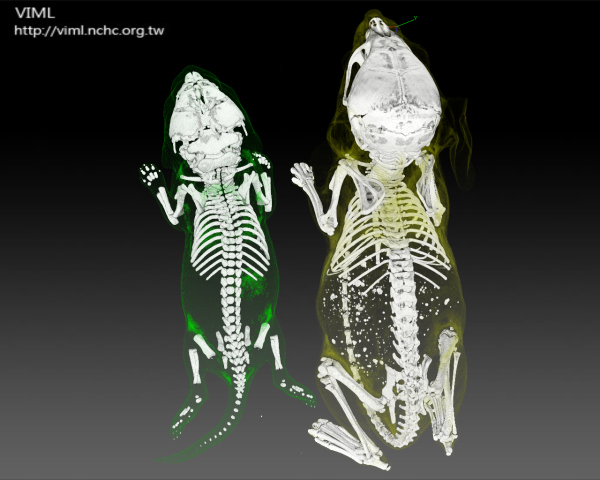
Volume rendering(图片来自网络)
二、图像处理
很多图像应用都需要对图像进行必要地预处理,如去噪、融合、分割、去雾、去模糊、视频去抖动等等,这个领域非常广泛,有大量模型和理论支撑。各位常用的Photoshop和美图秀秀里面成百上千的滤镜,可以说每一个背后都有一个数学模型。下面举一个例子。
2.1 分割
有一种简单的分割算法叫Superpixel,它可以把一幅图像分割成好多个小块,保证每一个小块中颜色都差不多。当然,还有其他许多分割算法,Superpixel的好处是简单,并且很容易推广到三维空间。
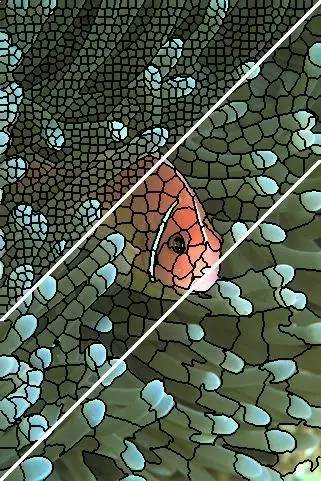
Superpixel分割
2.2 医学图像处理
经过分割后,图像被过度分割成了很多小块,这时就可以用模式识别的算法把属于同一类的小块们再合在一起。利用分割+分类的算法,可以把三维CT图像中的骨头全自动剔除。
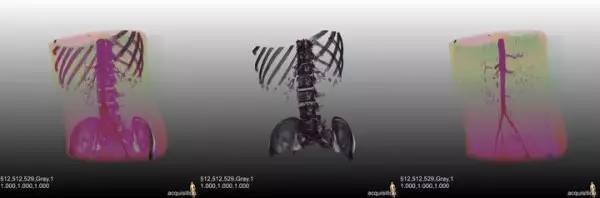
CT图像去骨的结果
三、计算机视觉
计算机视觉的目标是理解摄像机拍摄的图像,它的研究范围极其广泛,比如人脸识别、文字识别、目标追踪等等。在此介绍这一领域几个重要的方向。
大家都知道图像是二维的,而真实世界是三维的,上面介绍的图形学的原理是预先建一个三维场景然后研究摄像头看到的图像是什么样子,计算机视觉的野心则大得多:给你几幅二维图像,还原三维场景是什么。
3.1 一幅图像与测量
拿到一幅图像,可以获得平行关系,测量图像中不同物体的长度比值。

单目测量
3.2 两幅图像与双目视觉
拿到两幅在不同位置拍摄的同一场景的图像,就可以恢复出场景。
3.3 多幅图像与三维重建
计算机视觉在这二十年最激动人心的成果之一就是完成了从多幅图像序列重建三维场景的研究,从数学上和编程实现上解决了这一从二维重建三维的过程。试想你拿着摄像机在街上绕一圈,像CS地图那样的三维游戏场景就实时重建出来是多么激动人心啊。
三维重建更具体的定义是:通过同一场景的多幅图像,恢复出每一幅图像拍摄时相机的位置和姿态,以及每一幅图像上的每一个点在三维空间中的位置。

邻居家的一系列照片之一

恢复出的相机位姿和稀疏特征点位置

三维稠密重建
四、模式识别
模式识别研究输入和输出的关系,比如给你一系列病人的体征和谁有病谁没病,模式识别需要找一个模型建立体征和是否有病之间的函数关系。在图像处理、计算机视觉、医疗、生物、社会学中具有非常广泛的应用。
在The Elements of Statistical Learning的第一章里提出了四个典型问题:
-
垃圾邮件和正常邮件的区分
-
前列腺癌症确诊
-
数字手写字符识别
-
DNA序列和性状的关系
模式识别把这些具体问题背后共同的模式抽象出来,集中精力研究什么样的特征判别能力更强以及什么样的模型正确分类效率高。
五、综合应用
当你掌握的知识和技能足够多了,就可以做一些需要很多环节的大项目,随便举几个例子:
1. 在你家门口摆一台摄像机,自动识别和记录身高在1米7到1米8之间、身材姣好、长发、爱笑的女生的一举一动。一旦记录到一个符合要求的女生,将她加入数据库,以后单独更新,不同女生之间不能搞混。
2. 买一个机器人(带轱辘能自由移动并且安有摄像头的电脑),让它自己漫游探测环境,建立三维地图,搞清楚自己在哪,这也是计算机视觉中的一个已经理论上完美解决的重要问题:即时定位与地图构建 (Simultaneous localization and mapping, SLAM)。
3. 做一架飞机,它的功能是无论谁在追它都尽量甩掉;做一枚导弹,它的功能是尽量追上飞机,或者在附近爆炸;再做一个酷炫的供军区司令观赏的三维场景显示环境,把一些飞机和导弹放进去追着打去吧。
六、如何入手
6.1 看优秀教材
首先,学好高等数学、概率统计和线性代数(矩阵论)足矣,其他数学知识可以在具体学习模型的过程中掌握。
然后,看一些优秀的外文教材译文版,比如:
图形学:OpenGL超级宝典(第5版)、交互式计算机图形学:基于OpenGL着色器的自顶向下方法(第6版)
光线追踪器:光跟踪算法技术(Ray Tracing from the Ground Up)
图像处理:数字图像处理(第3版, 冈萨雷斯著),图像处理、分析与机器视觉(第3版)
计算机视觉:计算机视觉中的多视图几何(Multiple View Geometry in Computer Vision),计算机视觉:算法与应用(Computer Vision: Algorithms and Applications)
模式识别与机器视觉:模式分类(第二版),模式识别(第四版),The Elements of Statistical Learning, Pattern Recognition and Machine Learning
6.2 看文献
6.3 看代码
OpenGL、OpenCV、CUDA都有相应的文档和代码实例,也可以在网上找附有代码的教材,研究代码,模仿先人的代码。首先练习基本的函数,然后依照兴趣实现几个非常简单的应用。自己找一个问题,实现一个最简单的解决方案,然后不断精进代码、尝试新的模型,最后就精通了这个领域。
 平凉:职业教育搭平台
平凉:职业教育搭平台 习总书记关切事丨这一年
习总书记关切事丨这一年 国外创投新闻 印度教育
国外创投新闻 印度教育推荐内容
学习方法